|
Yuwen Tan
I'm a second-year PhD student in the Computer Science department at Boston University, where I am advised by Prof. Boqing Gong. |

|
ResearchI'm interested in computer vision, deep learning, and generative AI. Most of my research is about vision language models and continual learning. Some papers are highlighted. |
|
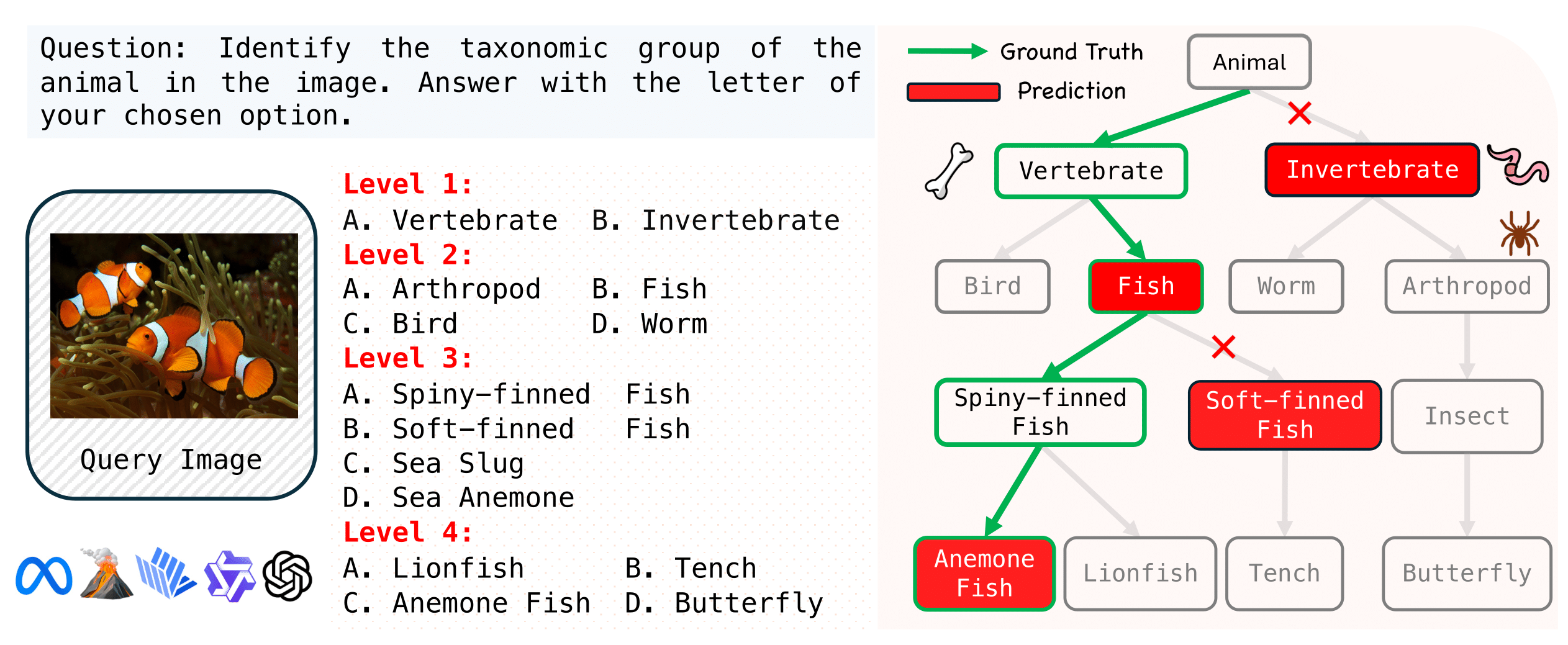
Vision LLMs Are Bad at Hierarchical Visual Understanding, and LLMs Are the Bottleneck
Yuwen Tan, Yuan Qing, Boqing Gong arXiv, 2025 project page / arXiv This paper reveals that many state-of-the-art large language models (LLMs) lack hierarchical knowledge about the visual world, failing to recognize even well-established biological taxonomies. |
|
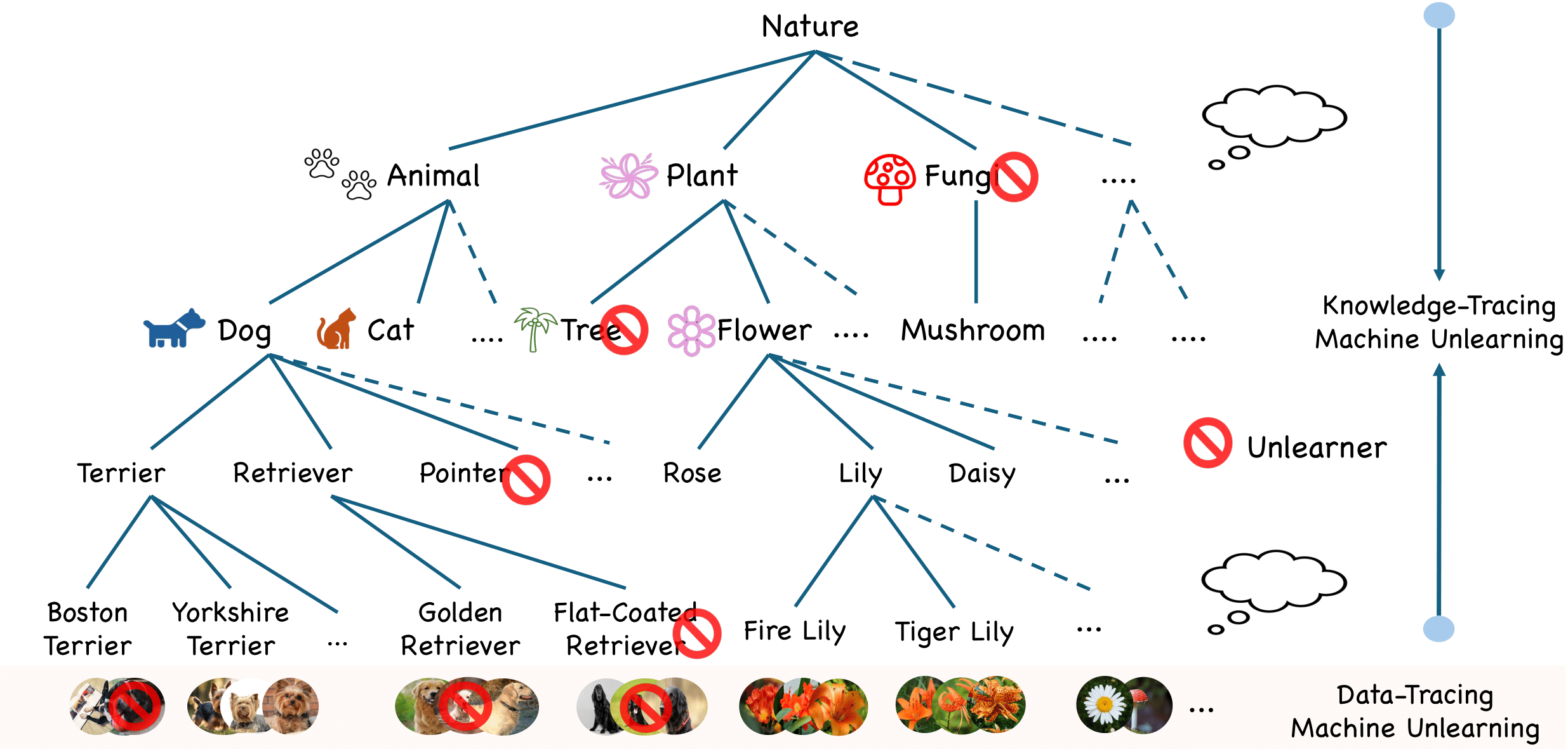
Lifting Data-Tracing Machine Unlearning to Knowledge-Tracing for Foundation Models
Yuwen Tan, Boqing Gong arXiv, 2025 project page / arXiv In this position paper, we propose to lift data-tracing machine unlearning to knowledge-tracing for foundation models (FMs). We support this position based on practical needs and insights from cognitive studies. |
|
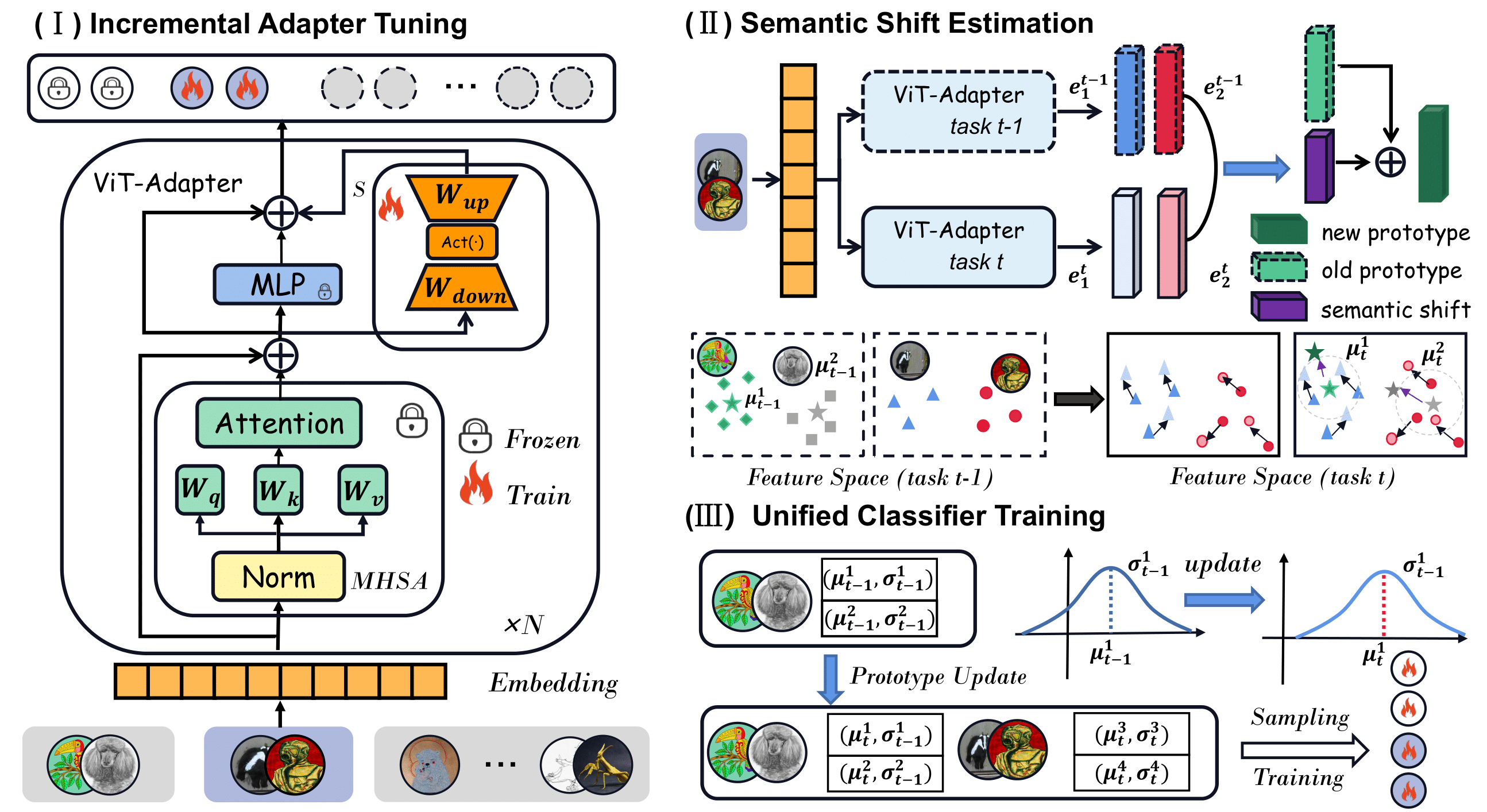
Semantically-Shifted Incremental Adapter-Tuning is A Continual ViTransformer
Yuwen Tan, Qinghao Zhou, Xiang Xiang, Ke Wang, Yuchuan Wu, Yongbin Li CVPR, 2024 video / code / The proposed method eliminates the need for constructing an adapter pool and avoids retaining any image samples. Experimental results on five benchmarks demonstrate the effectiveness of our method which achieves the SOTA performance. |
Miscellanea |
Academic Service |
Reviewer, CVPR 2026 Reviewer, ICLR 2026 Reviewer, NeurIPS 2025 Reviewer, TPAMI Reviewer, IJCV |